Analyzing Scan Results
In the previous section, you saw how the Scan Views dialog
could show issues in Scan Results based on their status, priority, and prediction. There are
more ways to show subsets of interest in the Scan Results table.
There are a variety of ways to organize your i18n issues:
- display only the results for a selected file or directory
- create and use views on the results
- display a specific issue in the context of its source code
- permanently filter a "false positive" detection
Show Results Based on File or Directory Selection
Use the Project Explorer to display scan results for a file
or directory selection. This is especially valuable when you're
working on a team and have divided up the work by source code.
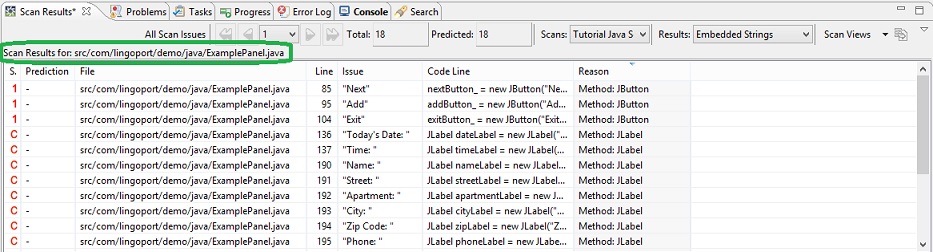
Within the Project Explorer, navigate to the file ExamplePanel.Java
by expanding src, then com.lingoport.demo.java.
Right-click on ExamplePanel.java and select Globalyzer/View
Scan Results For from the menu. Notice that the Scan Results
table shows just the results for that file.
To restore to the full set of results, right-click anywhere in Project
Explorer and select Globalyzer/View All Scan Results.
Sub-setting Scan Results
Another way to create a subset of the Scan Results table is
to use Globalyzer's Scan Views feature. This allows you to
display issues based on something they all share. You can set a
view based on text found in any of the Scan Results table
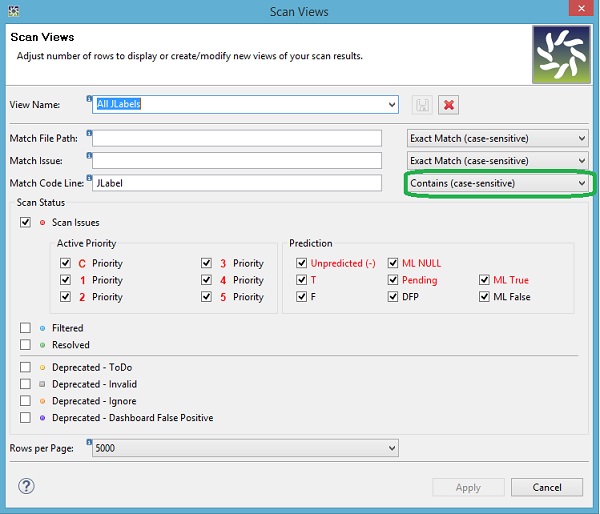
columns. To see how this works, let's create a view based on
common text in the Code Line column. Select the Scan
Views=>Manage Scan Views... option. Provide a View Name and fill in the text to match
on, select the Contains option, as shown below and click
the Apply button or the Save icon if you are
modifying an existing scan view.
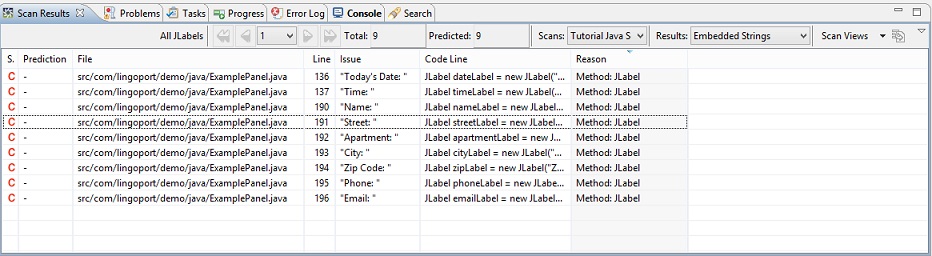
This new view is applied to the Scan Results table; you
will now see only the active issues that match the JLabel
settings.
Note: Scan Views apply to all your result types
(i.e. Embedded Strings, Locale-Sensitive Methods, Static
File References, General Patterns), not just the currently
displayed Scan Results.
To display the other active results again, select All
Scan Issues from the Scan Views dropdown.
Displaying Issues in the Editor View
The Scan Results table lets you directly open the source
file associated with a row. This helps you further analyze whether
the i18n issue will need to be refactored.
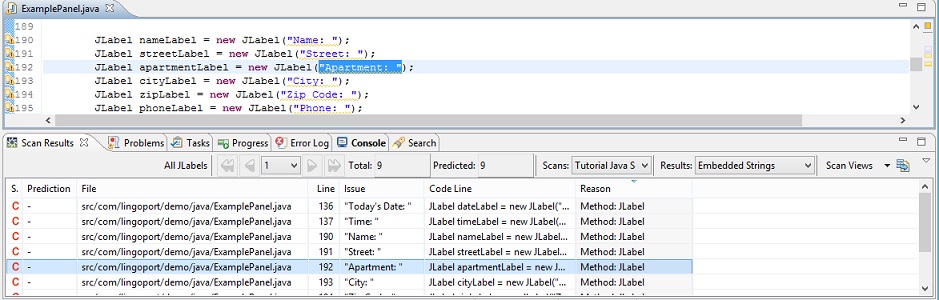
1. Find the Issue Apartment: in the table's Issue
column.
Tip: If this were a very large table with hundreds of
entries, you could also use the Find
in Results feature to locate a specific issue.
2. Double-click anywhere in the row containing the issue Apartment:.
The source file where the issue occurs is automatically opened in
the Editor view just below the table. Furthermore, the
issue is highlighted, as shown below.
Dealing with False Positive Issues
After scanning, there may be false positive issues in the results. There are three main ways of
removing false positive issues from your Scan Results.
- Go through the Scan Results and mark the prediction of known false positives as F and use the Scan View All Predicted Active
- Modify the source code to ignore the false positive issues
- Add rules to your Rule Set to filter more issues
For example, in our Scan Results, we have these two similar issues:
private static Locale locale("en", "US");
Locale locale = new Locale("en", "US");
The string literal "en" is a string that we do not want to translate. It is a compiler
directive and is not shown to the user.
We will explain the three alternatives for removing "en" from your Scan Results.
Mark the prediction for the issue False
One way to remove an issue from the Scan Results is to mark the prediction of the issue False.
Select one or more rows in the Scan Results table, right-click,
and choose Mark Prediction: FALSE(F). This sets the prediction of the issue(s) to F.
If you look at the Predicted count in the Scan Results, you will see this number decrease.
If you are using the Scan View All Predicted Active, the Scan Results table will not
displays issues with F predictions, so the issue will be removed from your view.
Per our example, in Scan Results, using the Scan View All Scan Issues,
select the "en" issue from the ExampleMain.java file,
right click, and set the prediction to F.
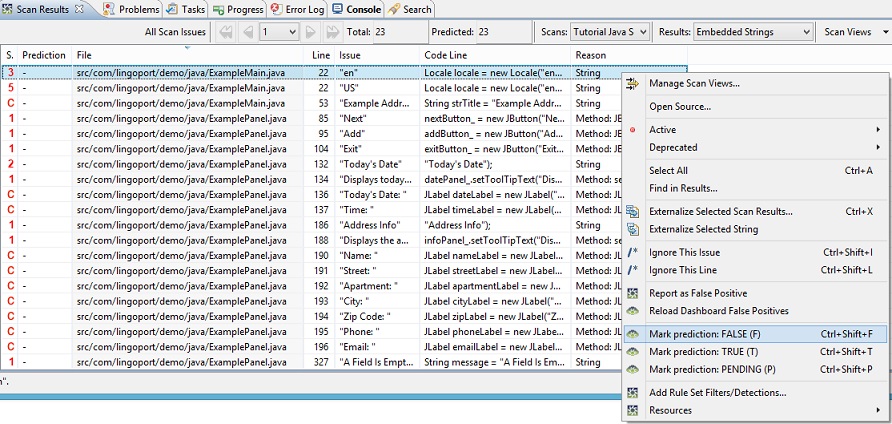
You will see the prediction marked F, and the Predicted count decrease.

If you switch your Scan View to All Predicted Active, the issue will be removed from the Scan Results.
You will see that the Total count and Predicted count are the same.

You will need to find, select, and mark the prediction of the second "en" string as False to remove it from Scan Results.
The advantage to using this approach is that you can directly change the Scan Results without modifying
source code or Rule Sets. The disadvantage of this approach is that you need to remember to
export the Prediction Report (via Machine Learning->Export Prediction Report) to save these
Scan Result modifications to be shared with other Workbenches, Lite, and the Dashboard.
Additionally, if the underlying source code changes too much, the prediction settings may
not be retained.
Please change your Scan View back to All Scan Issues and mark the prediction of the "en" issue(s) as Pending,
so we can explore other ways to remove the issue(s) from Scan Results.
Use an Ignore Comment
To ignore an issue, select one or more rows in the Scan Results table,
right-click, and choose Ignore This Issue to
ignore a single issue, or Ignore This Line to
ignore all issues on the line of code.
For example, we can select the following row from the Scan Results table:
private static Locale locale("en", "US");.
Double-click so that it opens in the Editor
view. Right-click in the Scan Results and select Ignore This Issue from the
dropdown:
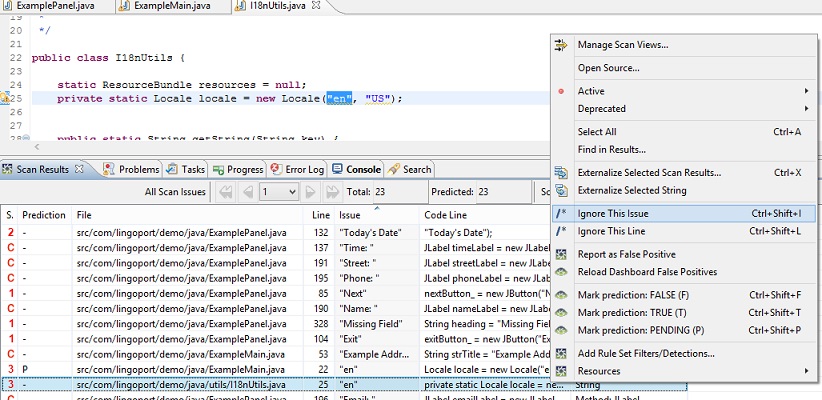
A comment will be added to the end of the source code line
as shown here:
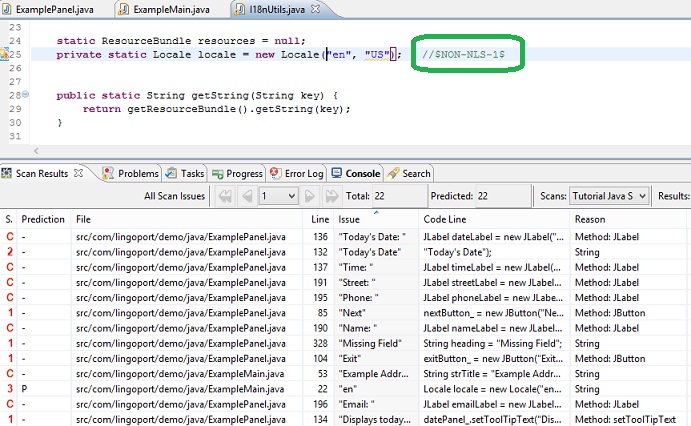
Globalyzer automatically rescans the file and removes the entry
from the Scan Results table. Notice how there is one fewer
Scan Result issue in both the Total and Predicted counts.
You would repeat the same steps to ignore "en" issue in ExampleMain.java's
Locale locale = new Locale("en", "US").
Another way to ignore issues in subsequent scans is to use
Globalyzer's other supported ignore comments:
Ignore Next Line, which inserts a comment above
the currently select line, and Start Ignore
and End Ignore
comments, which can be used to surround a block of code to ignore.
For example, click an issue in the Scan Results view and select
Fix Code from the Menu bar. You will see the various choices in the
dropdown menu.
You can also choose to insert a To Do comment above the current line
of code, which won't
affect the Scan Results table, but will allow you to put a
permanent note in the file.
The advantage of using this approach is that because the source code is modified, the results
are permanent,
so anyone using the latest source code will have the correct Scan Results.
The disadvantage is that this requires modifying the source code, and sometimes the people performing
this analysis don't have the ability to modify the source code.
Per our example, please modify your source code to remove the comments added when you chose Ignore this Issue,
so we can explore another way to remove the issue(s) from Scan Results.
Add rule to filter an issue
We can customize the rule set to filter out the "en" string.
We can do this by creating a String Content Filter to filter out all "en" strings.
1. Click on the View Scan Rule Set button in your
button bar. (You can also log in to the Globalyzer server). The
Globalyzer server page opens.
2. Select the Rule Set you are using for this tutorial and
click
String Content Filters.

3. Click the New String Content Filter button at the
top of the page.
4. Set the field so that the new content filter pattern is \Aen\Z,
a simple regular expression. This tells Globalyzer to
filter all "en" strings.
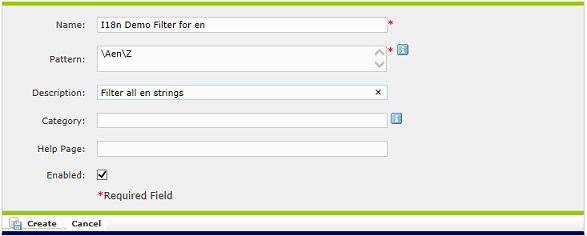
Click Create and then Done at the bottom of the Edit
String Content Filters page.
5. Select Project=>Reload Rulesets. Then scan the code again (Scan=>Single Scan).
The "en" issues have been filtered out of the active issues list.
The advantages of using this approach to remove issues from Scan Results
is that you do not need to modify the source code,
the results are permanent, and it will filter all "en" strings from the source code;
adding one rule to the Rule Set removed both "en" issues.
Adding rules to your rule set to filter issues is the preferred approach. However,
it can be difficult to determine how to filter a particular issue and requires some expertise in
writing regular expressions.
In this section, you organized the Globalyzer Scan results,
ignored some false positives, and filtered strings by customizing
the Rule Set used in this scan.
In the next section, you will prepare Globalyzer to fix the Active
issues listed in the Scan Results table.

 
|
